Anthropic's Most Powerful Model Is Now Public
Anthropic released Claude Fable 5 on June 9, the most capable model it has ever made publicly available. Here is what it actually does, and where it fits for a professional-services firm on the North Shore.

Key Takeaways
- ✓ On June 9, Anthropic released Claude Fable 5, which it calls the most capable model it has ever made generally available. It is the first public model from the higher "Mythos" tier.
- ✓ The gains that matter for professional services are in reading documents, reasoning over financials, and finishing long multi-step work, not chat tricks.
- ✓ It is available today. Paid Claude plans include it at no extra cost through June 22, after which it runs on usage credits.
- ✓ A stronger model does not change the hard part. The value comes from pointing it at one real workflow, with a person reviewing the output before it leaves the building.
If you run a law firm, an advisory practice, a family office, or an investment shop on the North Shore, the model behind the AI tools you already use just took a real step up. On June 9, Anthropic released Claude Fable 5, and described it as the most capable model the company has ever made generally available.
That sentence gets written about every model release. This one is worth a closer look, because the places Fable 5 improved are the exact places professional-services work lives: long documents, financial detail, and tasks that take many steps to finish. This is not a chatbot getting wittier. It is the engine getting better at the work you would actually hand to a junior associate.
In This Article
What Actually Shipped
Anthropic organizes its models in tiers. Until this week, the most capable tier, which it calls Mythos, was held back from general release. Fable 5 is, in Anthropic's words, "a Mythos-class model that we've made safe for general use." Same underlying engine as the restricted Claude Mythos 5, with safeguards added so the public can use it.
Two things changed in a way a business owner should care about. First, it reads and reasons over visual material, not just text. It can pull precise numbers out of a chart buried in a PDF, or read a scanned document, without a separate scanning step bolted on. Second, it holds long, multi-step tasks together far better than earlier models. Anthropic's own framing is blunt: "The longer and more complex the task, the larger Fable 5's lead over our other models."
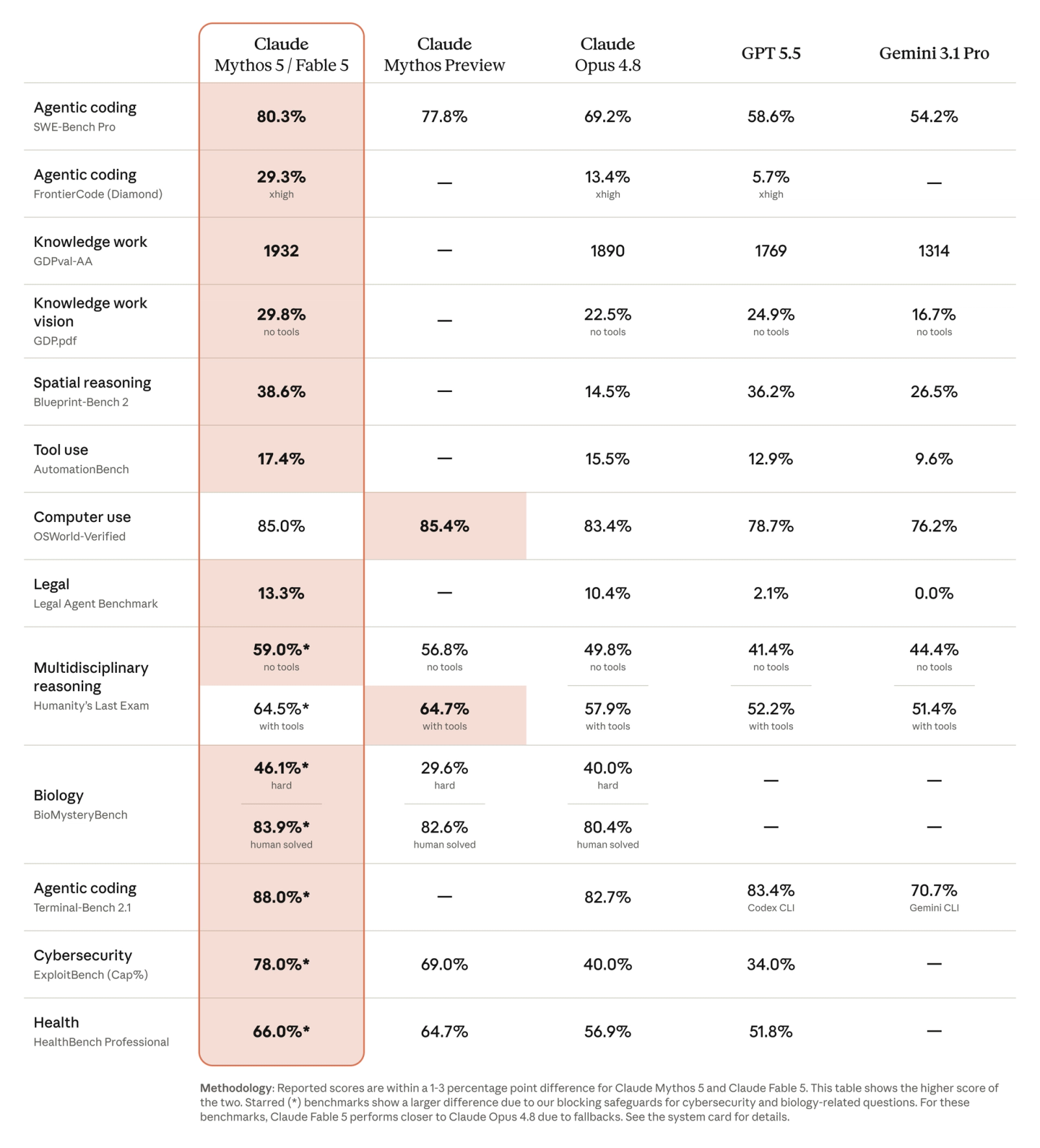
The benchmark numbers back up the claim. On GDPval, a test built around real expert knowledge work, Fable 5 scored higher than any model Anthropic compared it against. On finance specifically, Anthropic cites the research firm Hebbia reporting that Fable 5 earned the highest score of any model it had tested on senior-level financial reasoning. These are not coding-lab abstractions. They are the kind of reading, analysis, and judgment that fills a professional-services day.
"Fable 5's capabilities exceed those of any model we've ever made generally available."
Anthropic, Claude Fable 5 announcement, June 9, 2026Why This Matters for Professional Services
Most of the billable and non-billable hours at a firm go to the same handful of activities: reading something long, pulling the important parts out of it, comparing it against something else, and writing a first draft. A trust document against a prior version. A data room against a checklist. A stack of carrier quotes against each other. A year of statements against a question a client just asked.
That is precisely the work where Fable 5 improved. A model that reads a 200-page PDF, including the tables and the figures, and reasons over all of it at once is more useful to a lawyer or an analyst than one that is merely a better conversationalist. The honest framing is not "AI will run your firm." It is "the first-pass version of your most tedious reading-and-drafting work just got materially more reliable."
For a North Shore practice, that lands a little differently in each office. A trusts-and-estates attorney cares about consistency across documents. A wealth advisor cares about turning years of notes and statements into something searchable. An investment shop cares about getting through a data room faster. A family office cares about doing all of it without sensitive files leaving its control. The model is the same. The workflow worth building is specific to you.
Three Places It Earns Its Keep
These are illustrations of where a stronger model helps, not case studies. The pattern that works is the same every time: one narrow workflow, built carefully, with a person reviewing the output.
1. Document Review and Due Diligence
The slow, careful reading is exactly what the model is now good at.
A litigator could point it at a discovery set and ask for a timeline, the inconsistencies, and the documents that matter most. A corporate lawyer or an investor could run a data room against a diligence checklist and get a first list of what is missing or off-market. An estate attorney could compare a new trust against the prior instrument and surface every substantive change. The model does the first read. The professional does the judgment.
SAMPLE CLAUDE PROMPT
"Here are 18 documents from a data room. Compare them against the attached diligence checklist. List what is missing, what looks off-market, and any inconsistency between documents. Cite the document and page for every point. Flag anything you are unsure about rather than guessing."
2. Financial Analysis That Used to Need an Analyst
Reading statements and pulling numbers out of figures is where the finance gains show up.
This is the workflow where the independent benchmarks are strongest. An advisor could hand it a client's statements and a question and get a clean, sourced summary to check. An investment team could turn a CIM and a set of financials into a first-draft screening memo. Because the model now reads charts and tables inside documents directly, far less time goes to retyping numbers out of PDFs. The output is a draft a human verifies, not a decision the model makes.
SAMPLE CLAUDE PROMPT
"Read these three years of financial statements, including the charts. Summarize the revenue and margin trend, list the three numbers that most affect valuation, and note anything that looks inconsistent across the years. Show where each figure came from. Do not give investment advice."
3. Long, Multi-Step Work, Start to Finish
The bigger the job, the larger the gap between this model and the last one.
The clearest proof point came from outside professional services. Anthropic reported that Stripe used Fable 5 to complete a large code migration in a day that would otherwise have taken about two months by hand. The lesson is not about code. It is that the model can now hold a long, many-step task together without losing the thread. That is the same capability behind organizing a year of files, running a recurring review process, or working through a long checklist end to end, with a person approving the result.
SAMPLE CLAUDE PROMPT
"Here is a folder of client documents and our intake checklist. Sort each document by matter, list what is missing for each, draft the request emails for the gaps, and give me one summary table I can review. Queue everything for my approval. Send nothing."
How to Get Started
Try it on work you can already check
Take a document review or analysis you have already finished, give the same task to Fable 5, and compare. You know the right answer, so you can judge the model honestly before you trust it on anything new. The free window on paid plans runs through June 22, which makes this week a cheap time to test.
Pick one workflow, not ten
Choose the reading-and-drafting task your team does most and likes least. Write down its steps. A specific workflow with a clear input and output is something a model can actually do well. "Use more AI" is not.
Keep a person on every output, and mind the data
Nothing reaches a client or a court without a human review step. For confidential files, decide where the data is allowed to go before you start, whether that is a business plan with the right terms or private infrastructure you control. That decision is the project, more than the model is.
What This Does Not Replace
A more capable model raises the ceiling on what is possible. It does not change the discipline that keeps you out of trouble. Fable 5 still makes mistakes, still needs its work checked, and is not a lawyer, an advisor, or a fiduciary. It produces a first draft and a second opinion, not a final decision.
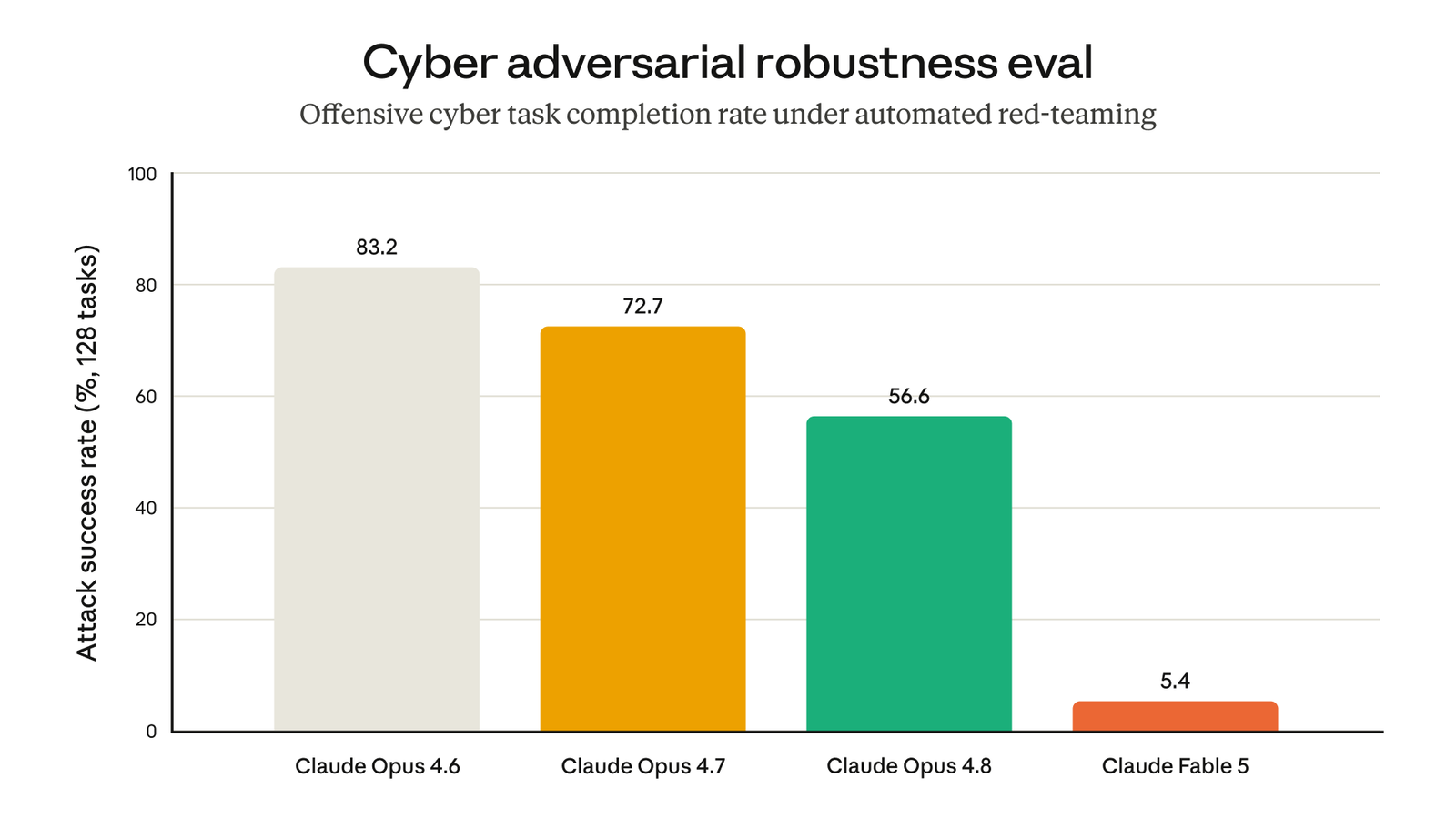
It also has limits by design. Anthropic built in safeguards that route a small set of high-risk requests, in areas like cybersecurity and biology, to its Claude Opus 4.8 model instead. The company says this happens in fewer than 5 percent of sessions, so more than 95 percent of work runs on Fable 5 with no fallback at all. For ordinary professional-services work, you will not notice it. It is worth knowing the guardrails exist.
From the Builder's Chair
Every time a new model lands, I get the same question from firms on the North Shore: should we switch? It is the wrong first question. The model is rarely the bottleneck. The bottleneck is that the work has never been written down clearly enough for anything, software or staff, to run it.
A better model makes a good workflow better and a vague one no less vague. So when I look at Fable 5, I am not thinking about the benchmark chart. I am thinking about which one of your reading-and-drafting tasks is painful enough, and repeatable enough, to be worth building around. Get that right and the model choice almost takes care of itself.
Start with the work you already check by hand. That is where a stronger model is safe to trust and easy to measure.
A Final Note on Timing
There is no prize for adopting a model on its release day. There is a real cost, though, to letting a capability like this sit unused for a year while the work it could have handled keeps landing on the same desks. The firms that pull ahead are not the ones that buy the most tools. They are the ones that picked one workflow, built it carefully, measured it, and expanded from there. Fable 5 simply makes the first workflow easier to get right.
If you want a clear-eyed read on where this fits in your practice, we offer a free 30-minute AI audit, in person on the North Shore or by video, with no obligation. You walk away with a one-page plan whether you work with us or not. Book a free AI audit and we will look at one real workflow together.
Frequently Asked Questions
What is Claude Fable 5? +
Claude Fable 5 is an AI model Anthropic released on June 9, 2026. The company describes it as the most capable model it has ever made generally available, and as the first public model from its higher "Mythos" capability tier, with safeguards added for general use. It is strong at reading documents, reasoning over financial detail, working with images and charts, and finishing long multi-step tasks.
How is it different from Claude Opus 4.8? +
Fable 5 sits above Opus 4.8 in capability and leads it on nearly every public benchmark Anthropic reported, with the largest gains on long, complex tasks. It also costs more to run, at $10 per million input tokens and $50 per million output tokens. Opus 4.8 remains a strong, less expensive choice for everyday work, and Anthropic still routes a small set of high-risk requests to Opus 4.8 even from within Fable 5.
Is it safe to use with confidential client documents? +
It can be, with the right setup. The model's capability is not the risk. The risk is sending confidential files somewhere they should not go, or removing the human review step. Decide where your data is allowed to live before you start, whether that is a business agreement with appropriate terms or private infrastructure you control, and keep a person reviewing every output that leaves the firm.
Do we need to switch to it right now? +
No. There is no penalty for waiting a few weeks, and the smart move is to test it on work you can already check before trusting it on anything new. Paid Claude plans include Fable 5 at no extra cost through June 22, which makes the next two weeks a low-cost time to compare it against your current model on a real task.
What is the first thing a firm should do with it? +
Pick one reading-and-drafting workflow your team does often and dislikes, give Fable 5 a task you have already completed by hand, and compare the output to the known answer. That tells you what the model is good at in your context, with no risk, and points to the first workflow worth building around.
Related Articles
An AI Course Built for Your Business
Generic AI courses teach general tools. A course built for your firm trains staff on actual workflows, from client letters to quarterly reviews, and puts a working prompt library in their hands rather than a certificate.
What AI Consultants Charge in 2026
Rates span from a $20-a-month Claude subscription to $7,500-a-day strategy from a global firm. Most North Shore professional services firms belong in the boutique implementation tier, where focused projects run $10,000 to $75,000.

Why AI Keeps Getting Cheaper for You
Inference costs fell more than 280 times in two years, and capable AI now runs on hardware you own. The math on waiting is worse than most firms think.
About the author

Written by
Michael Pavlovskyi
Founder, Bace Agency
Michael builds custom Claude and GPT workflows for insurance agencies, law firms, and PE firms on Chicago's North Shore. Speaker at Northwestern and Lake Forest College on practical AI adoption for professional services.
Connect on LinkedInWant to see how AI fits in your firm?
Book a free 30-minute AI audit. No obligation, no pitch deck.
Book a Free AI Audit →