We Spent $20,000 to Run AI Locally
We bought two Mac Studios to run AI in house, and learned where local models pay off and where they do not.

Key Takeaways
- ✓ We were spending more than $4,000 a month on the Anthropic API. We bought two Mac Studios for over $20,000 to see if local open models could replace it.
- ✓ They could not, not for the hard work. Open models like Kimi K2.5 and Qwen run on the hardware, but they did not come close to Claude on the reasoning we rely on.
- ✓ The economics are simple. If you spend a few hundred dollars a month on an API, $20,000 of hardware never pays for itself. The math only starts to work at much higher volume.
- ✓ Local AI still earns its place for one thing: privacy. The data never leaves the machine. For sensitive files, that is worth more than the speed or the savings.
Our own AI bill got our attention before any client's did. We run a lot of work through the Anthropic API, and one month it crossed $4,000. That is real money for a small firm. So we did what a lot of owners on the North Shore are quietly wondering about: we asked whether we could buy the hardware once and stop renting the model by the token.
The pitch to ourselves was clean. Buy strong machines, download open models that anyone can run, and bring the work in house. No per token bill. The data stays on our own equipment. On paper it looked like a clear win for a family office, an RIA, or any firm that handles sensitive files and is tired of a usage meter running.
So we spent the money and ran the test for real. Here is what actually happened, including the part where the math did not work the way we hoped.
What We Bought and Ran
The hardware was two Mac Studios, each with 512GB of unified memory. We were lucky to get them. Apple has since pulled the 512GB option from its store as memory prices climbed, so this exact configuration is now hard to buy at all, per Tom's Hardware. At launch each one was $9,499. Two machines, plus cables and a hub, put us over $20,000.
The reason for two machines is size. The best open models are too big to fit in one computer's memory. We used a tool called EXO, which splits a single model across several Macs and runs it as one. It sits on top of MLX, Apple's own framework for running models on its chips. With both Studios linked, the model loads half into one and half into the other.
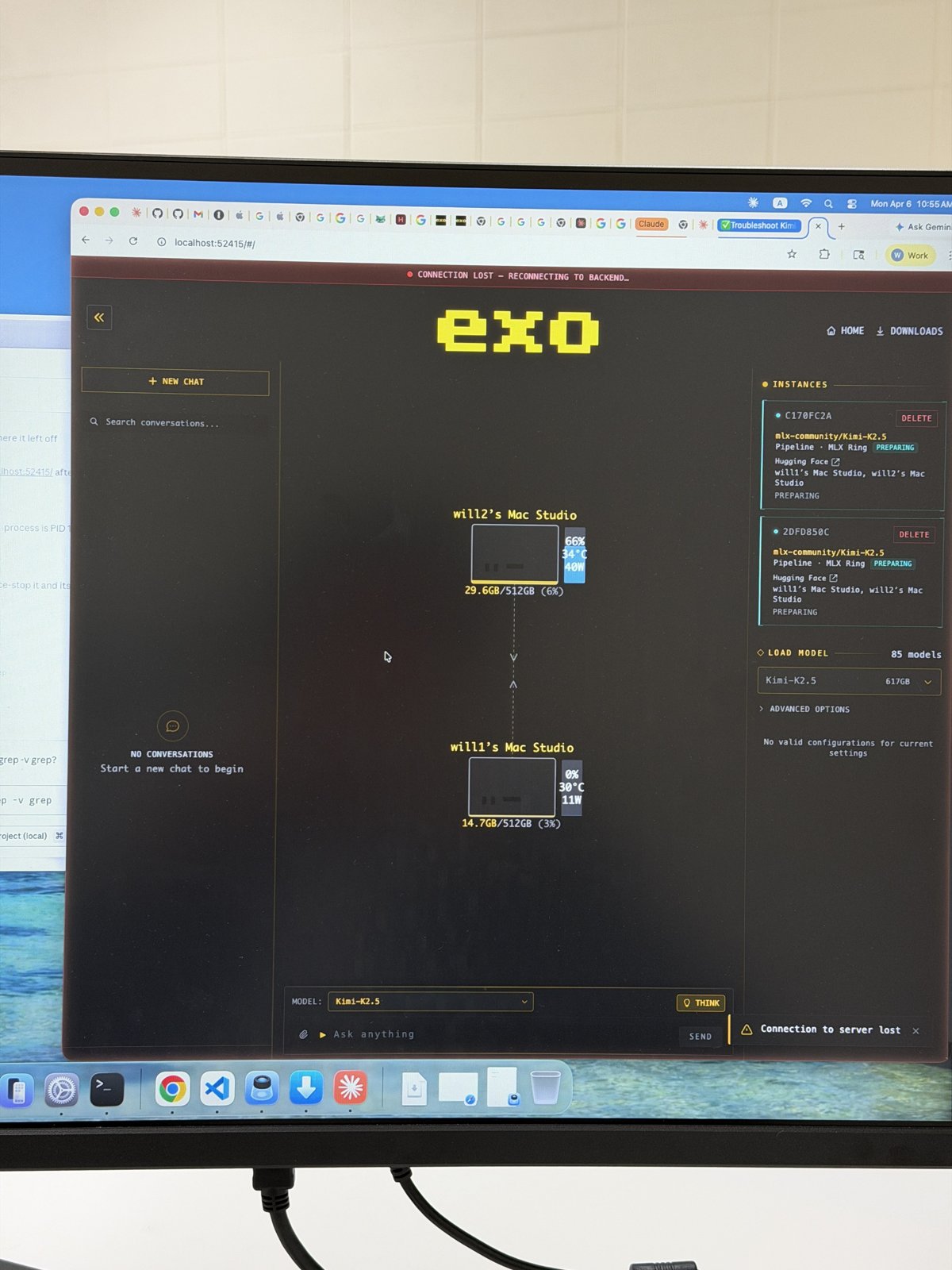
We tested two models. Kimi K2.5, the newest model in Moonshot AI's Kimi K2 line, ran at about 25 tokens per second. That is fine for a job you hand off and check later, and slow if you are waiting on it live. We also ran Qwen in an 8-bit version, which was meaningfully faster. Both are open weight models you download once and run yourself, with no usage bill behind them. For a firm that wants AI on hardware it owns, that part is real.
"The hardware did everything we asked. The problem was never the machines. It was that the open models are not as smart as the one we were trying to replace."
Michael Pavlovskyi, Bace AgencyWhy This Matters for Family Offices and RIAs
A family office or an RIA is exactly the kind of firm that should care about this question, and for two reasons that pull in opposite directions. The first is privacy. These firms hold tax returns, trust documents, account statements, and family details that should not sit in anyone else's system, even briefly. The idea that the file never leaves a machine in your own office is genuinely appealing, and it is the strongest argument for going local. It is the same case I made for running AI in house for Highland Park family offices.
The second reason is cost, and this is where most owners get the picture wrong. The hardware is a large fixed cost up front. The API is a small cost per use. Renting the model only beats owning it once you are using a great deal of it. We learned that the hard way, with our own money, which is the same lesson behind the real cost of an AI project. The work a family office reclaims with AI is real. You do not need to own a $20,000 cluster to get it.
So the honest framing for this audience is not local versus cloud as a money decision. For almost every firm, the cloud API is cheaper until you are very large. The real question is whether a specific set of your files is sensitive enough that you want them processed on a machine you control, even if it costs more. That is a privacy decision, not a savings decision, and the two get confused constantly.
Where Local Models Actually Win
The work is repetitive, the volume is high, and the files should not leave the building.
Local models did not replace our hardest work, but they were perfectly good at the boring, repeated work. Sorting a stack of documents by type. Pulling the same fields out of statements that all look alike. Flagging which files mention a particular account or entity. None of that needs the smartest model in the world. It needs a competent one that runs on material you would rather not send anywhere.

SAMPLE CLAUDE PROMPT
"You are sorting documents for a family office. For the file below, return three fields. Type: tax document, account statement, trust document, invoice, or other. Entities: every person, trust, or company named. Account references: any account numbers or fund names mentioned, or NONE. Do not summarize or interpret. Return only those three fields."
Where They Fell Short
The reasoning we actually pay for is the part the open models could not match.
The work that justified our API bill in the first place was the harder kind. Reading a messy situation and explaining it clearly. Catching the inconsistency a junior person would miss. Drafting something that needs judgment, not just pattern matching. On that work, neither open model came close to Claude. The gap was not subtle. It was the difference between an answer we could send and one we would have to redo.
This is the part the hardware cannot fix. A faster machine runs a weaker model faster. It does not make the model smarter. We could buy more Mac Studios and still not close that gap, because the limit is the model, not the silicon. For a firm whose AI use is mostly the hard, judgment heavy work, local open models are not a replacement yet. They are a second tool for the simple, high-volume jobs.
SAMPLE CLAUDE PROMPT
"Compare these two account statements from different quarters for the same client. List every change in holdings, flag any that look inconsistent with the stated investment policy, and explain in plain language what a client would want to ask about. Note where you are unsure rather than guessing."
One More Thing About Chinese Models
The worry is reasonable, and running the model locally is the answer to it.
Kimi and Qwen are both Chinese models, and owners ask about that immediately. It is a fair question. The reassuring part is that running the weights on your own machine is the answer to the worry, not the cause of it. The model is a file of numbers. When it runs locally, nothing about your prompt or your documents goes to China, or to Moonshot, or to anyone. There is no connection out. The data never leaves the building.
That is the whole point of going local, and it holds no matter who trained the model. You are not trusting the model maker with your files, because the model maker never sees them. You are only trusting the math to run on your own hardware. For a firm that is nervous about where a Chinese model came from, local is the version that removes the part you were actually worried about.
How to Get Started
If you are weighing this for your own firm, do not start by buying hardware. Start by sorting your AI work into two piles and being honest about the cost.
Add up what you actually spend
Look at your real monthly API cost, or estimate it from how much you use a paid AI tool. If it is a few hundred dollars a month, a $20,000 machine will not pay for itself for years, if ever. Be honest about the number before you fall in love with owning the hardware. The meter feels worse than it costs.
Separate the privacy question from the money question
Decide which of your files are sensitive enough that you want them processed only on a machine you own. That is a real reason to go local. Saving money usually is not, unless your volume is large. Keep the two reasons apart, because mixing them is how firms buy hardware they did not need for a problem they did not have.
Match the model to the task
Use a strong cloud model for the hard, judgment heavy work. Use a local open model for the repetitive, high-volume, sensitive jobs where good enough on a private machine beats brilliant on someone else's server. Most firms need both, and the skill is knowing which work goes where.
What This Does Not Replace
Buying hardware does not buy you a better model. We learned that for $20,000. The Mac Studios are excellent machines and they did exactly what they promised. The open models on them are useful for a real but narrow set of jobs. What they are not is a drop-in replacement for the frontier model we were paying for, and no amount of additional hardware changes that.
It also does not replace the judgment about where AI belongs in your firm in the first place. The most expensive mistake here is not the API bill. It is spending $20,000 to solve a problem you could have solved with a $200 a month subscription, or skipping the local setup on the one batch of files that genuinely needed it. Getting that call right is worth more than the hardware either way.
If you are trying to make this call for your own firm, you do not have to spend $20,000 to learn what we already learned. A free 30-minute AI audit is the right starting point, in person on the North Shore or by video. We will tell you honestly whether local hardware is worth it for you, or whether you are better off staying on the meter. No obligation.
Frequently Asked Questions
Is it cheaper to run AI locally instead of paying for an API? +
Usually not, unless your volume is very high. Local hardware is a large fixed cost up front, while an API is a small cost per use. We spent over $20,000 on two Mac Studios while our API bill was a few thousand a month, and the hardware still did not obviously pay for itself. For most small firms a cloud API stays cheaper until you are using a great deal of it. The strongest reason to go local is privacy, not savings.
Are open models like Kimi and Qwen as good as Claude? +
For simple, repetitive work they are good enough. For sorting documents, pulling fields, and flagging files, a local open model does the job. For the harder work that needs real reasoning and judgment, we found they did not come close to Claude. The gap was clear, not marginal. Open models are a second tool for the easy, high-volume jobs, not a replacement for a frontier model on the hard ones.
Is it safe to run a Chinese AI model on our own machines? +
Running the model locally is what makes it safe, because the model never connects out. The weights are a file of numbers. When it runs on your own machine, nothing about your prompts or documents goes to the company that made it, or anywhere else. You are trusting the math to run on your hardware, not trusting the model maker with your files, because the model maker never sees them.
Why do you need two Mac Studios for one model? +
The largest open models are too big to fit in a single machine's memory. A tool called EXO splits one model across several Macs and runs them together as if they were one computer. Each Studio holds half of a large model like Kimi K2.5. For smaller models one machine is plenty. The two machine setup is only needed when the model itself is very large.
Should my family office or RIA buy a local AI setup? +
Only if you have a specific set of files sensitive enough that you want them processed on hardware you control, and ideally enough volume to use the machine well. If your reason is saving money, the numbers rarely work for a small firm. If your reason is privacy on a real category of sensitive work, it can be the right call. Price your actual use first, which a short audit does before you spend anything.
Related Articles
AI Fixes Family Office Bill Pay First
Bill pay is the quiet money pit of every family office. A small team, serious capital, and invoices checked by hand across five entities. Here is how AI closes the gap.

AI Due Diligence for Search Fund Operators
A searcher gets one shot to diligence a company, often alone and on a clock. Here is what a working AI diligence workflow actually does, and what it does not replace.
The SEC's 2026 AI Rules for Investment Advisers
Everyone is waiting for the SEC's new AI rulebook. It does not exist. Here is what examiners actually check instead, and the three documents that get a small RIA ready.
About the author

Written by
Michael Pavlovskyi
Founder, Bace Agency
Michael builds custom Claude and GPT workflows for insurance agencies, law firms, and PE firms on Chicago's North Shore. Speaker at Northwestern and Lake Forest College on practical AI adoption for professional services.
Connect on LinkedInWant to see how AI fits in your firm?
Book a free 30-minute AI audit. No obligation, no pitch deck.
Book a Free AI Audit →